Running Deduplication
Navigate to Deduplication from your project dashboard.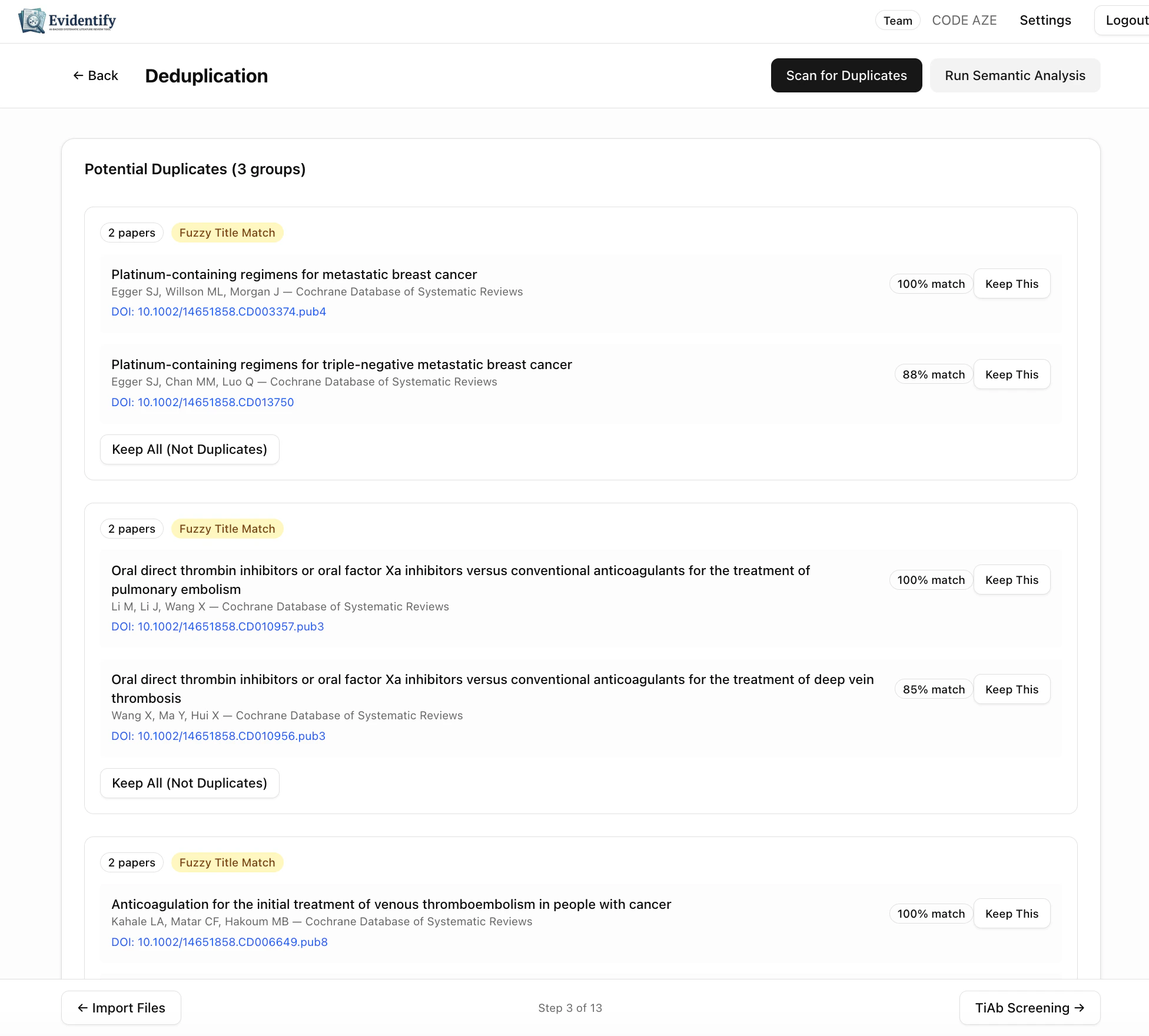
Scan for Duplicates
Fast scan using DOI matching, exact title matching, and fuzzy title matching (85%+ similarity). Takes seconds.
Run Semantic Analysis
Deep scan using AI-powered semantic similarity. Catches papers that describe the same study with completely different wording. Takes longer but finds more duplicates.
The 4 Detection Layers
Reviewing Duplicate Groups
Each group of potential duplicates shows:- Match type badge (e.g., “Fuzzy Title Match”)
- Similarity score for each paper (e.g., 100%, 88%, 85%)
- Full metadata: title, authors, journal, DOI